
You have en.json in your repo. You want de.json, fr.json, and ja.json to stay in sync as you add or change strings, without making someone manually translate every key in every PR. You don't want to buy a full TMS.
Two paths you can take from here. Build the CI translation step yourself: maybe a day of work to get the basics, plus ongoing maintenance as edge cases pile up. Or use a tool that does this out of the box (Localhero.ai, which we are building, is one; Tolgee and SimpleLocalize are others), and skip straight to the workflow. This post walks through the DIY pattern in detail so you know what's involved, then closes with where the trade-off shifts.
Assumes you're using a code-native i18n setup (JSON for React/Next.js, YAML for Rails) and that you control the CI config.
What breaks first
The naive approach is run a script that translates everything on every PR.
That works for a week, then consistency starts to slip in ways the script can't catch on its own. Some examples that you easily run into:
- Placeholders get translated.
Welcome, {name}!becomesBienvenue, {nom}!in French, your app crashes because{nom}isn't a valid interpolation key. - Plural forms break. ICU plural syntax (
{count, plural, one {# item} other {# items}}) trips up most generic translation APIs, even though it's the standard. - Glossary terms drift.
Workspace
gets translated three different ways across PRs because the model has no memory of how it was translated last time. - Reviewing translations becomes someone's problem. A PM, designer, or native-speaker wants to check the new copy before merge. A YAML diff in a PR isn't a review surface.
- The CI step takes forever. Translating 50 keys × 5 languages with sequential API calls adds 2-3 minutes to every PR.
- JSON or YAML structure breaks. Nested objects get flattened, key ordering changes, comments disappear in YAML, the diff is unreadable.
Tying it together: the script can produce a translation reliably, it just can't produce a consistent translation across the dozen places where the same concept appears, keep brand voice steady, or surface that translation for the people who need to check it. A purpose-built tool like Localhero.ai aims to handle all of these in a consistent way.
The pattern that works
Here's the shape of a CI translation workflow that holds up over time. Pick the tools that fit your stack, but the steps are the same:
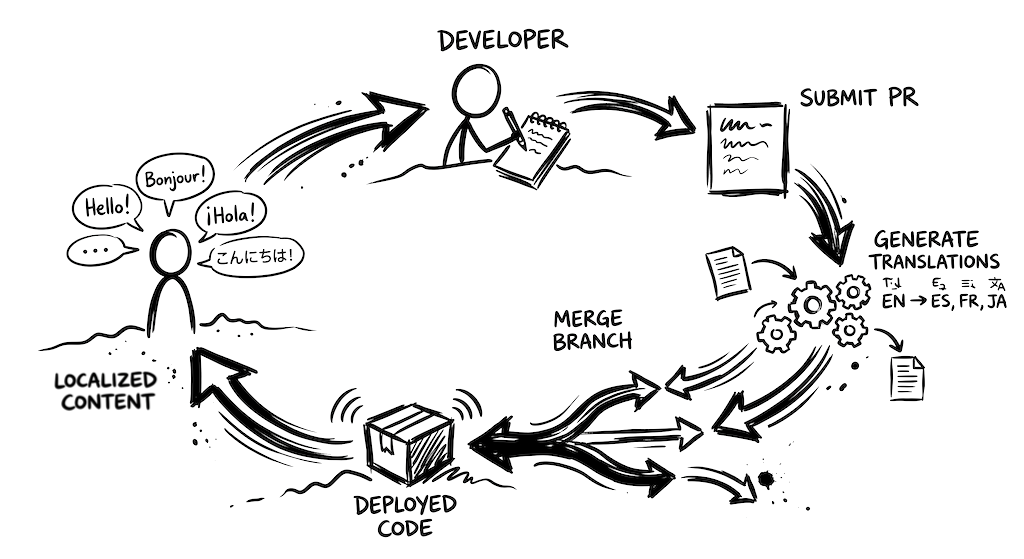
1. Detect changed keys, not changed files
The trick is diffing against the base branch's locale file, not just translating everything you see. In a JSON file:
# Compare en.json on this branch against the base
git diff origin/main -- locales/en.json
Heads-up: git diff origin/main only works in GitHub Actions if you fetch the base ref first. Use actions/checkout@v4 with fetch-depth: 0, or add an explicit git fetch origin main step. Otherwise origin/main won't exist in the runner's checkout.
Parse the diff to find:
- Added keys that don't exist in target locales yet
- Modified keys where the English value changed (target translations are now stale)
- Removed keys that should also be removed from target locales
Translate only those three sets. Everything else stays as-is. This is the biggest cost saver, and it's what keeps already-shipped translations from drifting.
2. Preserve placeholders before sending to the model
LLMs sometimes translate things they shouldn't. The fix is mechanical: extract placeholders, replace with sentinel tokens, translate, then put the originals back.
The core of the fix is a regex that matches the common placeholder formats:
const PLACEHOLDER_REGEX = /(\{\{?[^}]+\}?\}|%\{[^}]+\}|%[sdif])/g;
Extract matches into sentinel tokens (__PH0__, __PH1__) before sending to the model, restore them after. Catches i18next, Rails I18n, and printf-style. Extend the regex for whatever else your stack uses. Two cases worth knowing about up front:
- ICU MessageFormat plurals like
{count, plural, one {# item} other {# items}}have nested braces, so a flat regex like the one above will mangle them. Either handle ICU as a separate parse step, or pick a translation tool that knows ICU natively. - React-i18next interpolation tags like
<0>{{name}}</0>need a different strategy: you'll usually want the model to keep the tag structure but translate the text between tags.
3. Pass the glossary in the system prompt
Whatever model you're using (Anthropic, OpenAI, DeepL with its glossary feature, or anything else), include your product terms in the prompt or in the API's glossary parameter. A minimal system prompt:
const systemPrompt = `You are translating from en to ${targetLocale}.
Glossary (use these translations exactly):
- "Workspace" → "Arbeitsbereich" (de) | "Espace de travail" (fr)
- "Dashboard" → keep as "Dashboard" (do not translate)
- "Subscription" → "Abonnement" (de) | "Abonnement" (fr)
Style: professional but approachable. Use informal address (du in German).
Return only the translation, no explanation.`;
The glossary file lives alongside your locale files in the repo. The CI step reads it and injects it into the prompt.
What looks simple in the snippet is more involved at scale. Stuffing a growing list of glossary terms into every prompt pollutes context and confuses the model. The trick is selecting only the terms relevant to the current batch, layering tone and style guidance without overloading the prompt, and giving the model examples for the formats it struggles with. Different models also want different prompt shapes. Localhero.ai does a lot of work to get this right for each translation, for example relevant glossary terms only, tone-and-style settings injected separately, examples from translation memory.
4. Validate the output before committing
After translation, validate:
- Valid JSON or YAML structure. Parse it; abort the run if it fails.
- All placeholders preserved. Compare the count and content of
{...}in source and translation. - No drift in untranslated keys. Diff against the previous version of the target file; only changed keys should show up.
If any validation fails, post a comment on the PR with the specific failures and don't commit. Better to require human attention than ship broken JSON.
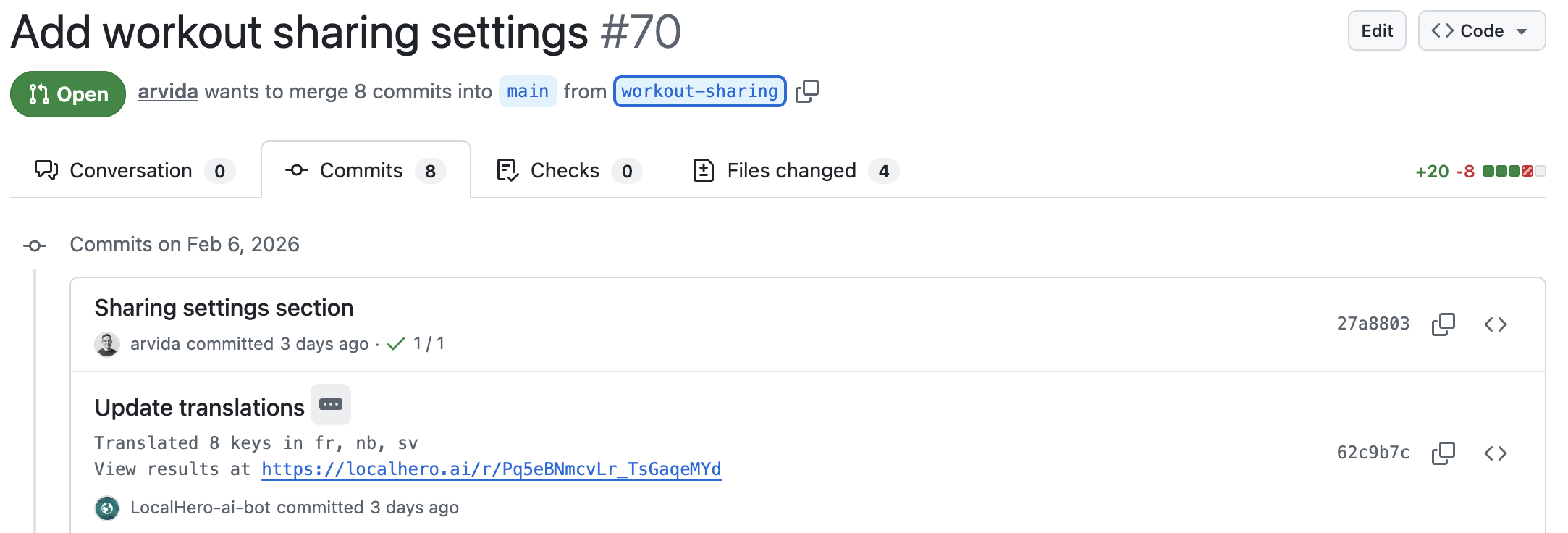
5. Commit translations back to the same PR
This is the part that makes the workflow feel native to git. Translations land in the same PR as the source change, with the same commit history. Reviewers see the full picture in one place.
A minimal GitHub Actions step:
- name: Translate changed keys
run: node scripts/translate-changed.js
env:
OPENAI_API_KEY: ${{ secrets.OPENAI_API_KEY }}
- name: Commit translations
run: |
git config user.name "translation-bot"
git config user.email "bot@yourcompany.com"
git add locales/*.json
git diff --staged --quiet || git commit -m "Auto-translate changed keys"
git push
if: github.event_name == 'pull_request'
YAML quirks worth knowing
YAML adds some sharp edges that JSON doesn't:
- Anchors and aliases. If your
en.ymluses&and*, a naive translate-and-write step will expand them in the output, which technically still works but makes the file unreadable. The fix: detect anchors and translate the canonical version only. - Quoted vs unquoted strings. YAML allows both. Most parsers preserve the style on round-trip, but some don't. If your diffs are mostly quote-style changes, your YAML library is normalizing on write. Look for the option to preserve original style.
- Comments. YAML comments don't survive most parsers' round-trip. If your team uses comments to annotate translation keys (like marking placeholder meanings), you need a parser that preserves them. In Ruby,
Psych(the stdlib YAML library) drops comments by default, there's no built-in round-trip mode. In Node, eemeli/yaml v2.x preserves comments out of the box when you useparseDocument()rather thanparse(). In Python,ruamel.yaml(aPyYAMLfork) is the standard option for comment-preserving round-trips. - Rails plural keys. When a YAML key has a pluralization shape like
apples: { one: "1 apple", other: "%{count} apples" }, theoneandotherkeys aren't independent translations, they're plural forms of the same logical string. Polish, Russian, and Arabic need additionalfew/many/zeroforms that don't exist in your English source. Treat plural groups as a unit and let the model know which form is which, not as standalone strings.
When DIY makes sense, and when it doesn't
The pattern above can be built in a day with a coding agent, plus some time for QA and validation. Whether to keep building on it depends on where your team is heading.
DIY keeps working when:
- You ship to two or three target languages, mostly product UI strings
- A small enough team that one person can own the translation script
- Low churn in the glossary (you don't add new product terms often)
- No non-technical reviewers (translations being final-on-merge is fine)
- You're an engineer who enjoys this kind of plumbing
DIY starts to hurt when:
- More target languages means managing parallel calls, retries, and rate limits in your script. Doable, but fiddly enough that the maintenance starts to compete with shipping.
- A glossary that grows weekly (more time updating the prompt than translating)
- Non-technical teammates want to review or tweak translations without a PR
- Translation memory matters for keeping things consistent as you ship, while letting the team adjust deliberately when the product or voice evolves. Hard to build well in a script.
- Brand-sensitive copy needs a workspace for the whole team, not a YAML diff in GitHub
For product teams shipping continuously, Localhero.ai (which we are building) runs the same CI pattern as above and handles the parts that get painful at scale: glossary management with a UI the whole team can edit, translation memory, parallel API calls, JSON and YAML validation, plural-form handling, and a PR review interface for non-technical teammates. Tolgee is an open-source alternative if self-hosting matters. SimpleLocalize is another option in the same category.
A full TMS (Lokalise, Phrase, Crowdin) is a different category, built around translator coordination workflows and tend to be overkill for code-native, agent-driven setups. We've written about when a TMS is and isn't the right fit.
If you find yourself maintaining the script more than you're shipping features, that's the signal to either invest more or hand off to a tool that already does it.
FAQ
How do I translate JSON locale files in CI?
The working pattern: diff against the base branch to find changed keys, protect placeholders before sending to the LLM, pass your glossary in the system prompt, validate output structure, and commit translations back to the same PR. About a day of work for a basic version. Tools like Localhero.ai, Tolgee, and SimpleLocalize handle this out of the box if you'd rather not maintain it yourself.
Why shouldn't I just translate every locale file on every PR?
You'll re-translate keys that haven't changed, which wastes API calls, costs money, and risks introducing drift in translations you've already shipped. Diffing against the base branch and translating only what changed solves all three.
How do I stop the LLM from translating placeholders like {name}?
Mechanical fix: before sending text to the model, extract placeholders and replace them with sentinel tokens (__PH0__, __PH1__). Translate. Restore the originals. Works for the common formats (i18next, Rails I18n, printf-style). ICU MessageFormat plurals need a separate parse step because of nested braces.
Can a DIY script handle Polish, Russian, or Arabic plural forms?
Yes, but it takes more care than the standard { one, other } pattern. Polish has one / few / many / other, Russian has one / few / many / other, Arabic has zero / one / two / few / many / other. The script needs to know which plural categories the target language uses (CLDR has this data) and ask the model for each form explicitly. Most generic translation APIs trip up here, which is one reason a tool with native plural-form handling is worth it once you ship to those languages.
Does this pattern work for PO files and Django?
Yes. PO files (gettext) work the same way conceptually: diff against the base branch, find changed msgid entries, translate, write them back. The differences worth knowing: PO uses msgid_plural for plurals (so the script needs to handle plural-aware msgstrs per CLDR category for each target language), and msgctxt for disambiguating same-string-different-meaning cases. Comments above each entry are also load-bearing, since translators (or LLMs) rely on them for context. Localhero.ai supports PO files natively, including plurals and contexts, so it works out of the box for Django, GNU gettext setups, and any other gettext-based stack.
How does Localhero.ai compare to building this myself?
Localhero.ai runs the same CI pattern this post describes (diff, protect, prompt with glossary, validate, commit back). It also handles the things that get painful at scale: glossary management with a UI the whole team can edit, translation memory across PRs, parallel API calls for many languages, JSON and YAML validation, plural-form handling for the languages with more than two forms, and a PR review interface for non-technical teammates. Whether to build or use a tool depends on how many languages you ship, how often the glossary changes, and whether anyone outside engineering will touch translations.
Further reading
- How to Automate i18n Translations with GitHub Actions: 3 Approaches - DIY, dedicated tools, and self-hosted setups with working configs
- SaaS Localization Without a TMS - when a TMS is and isn't worth it
- Using the OpenAI API for App Translation - the longer-term cost of the DIY path
- Translating your i18n files with Claude Code or Cursor - the agent-aware angle
- How to Localize a Ruby on Rails App - Rails-specific i18n basics
- How to Localize a React App (and Next.js) - React/Next.js i18n basics